Algorithm Update
As discussed, we think it might be a good idea to stop the fitting in an algorithmic way. As we noticed, as we go deeper and deeper the ratio of failed fits to successful fits increases. I haven’t implemented this in the code (yet), but it is something to come back to if we decide this is a good way to go.
- One we have all our successful fits, we sort them based on some parameter specified by the user (default would be magnitude or surface brightness)
- As we fit, we store the previous, say, 50 results (successful or failure) in an array.
- After 50 fits, we start to check the ratio of successes to failures.
- If the ratio slips too much into being failure dominated, (say, 50 or 60%), we stop the fitting.
This would be a good automated way to stop the fitting once too many failures are occurring.
ACEnet Meeting Planned!
During this week, I spent some time moving some of my work onto the Cedar cluster. For whatever reason, the bash script that I used on my previous pipeline is no longer valid for my new pipeline. This means it was definitely time to schedule a meeting with a rep from ACEnet.
On Wednesday afternoon next week, I will meet with Ross Dickson (who I have already met from the parallel computing school!). The things I will go over are as follows:
- How do I properly get Astropy, Photutils, and other Conda packages setup, and do I have to run this setup for every job?
- How can I handle fail conditions (such as the dreaded infinite loop issue). Something I might do is have an internal timer running on a different thread, and any last-minute commands (such as image deletion) will always be run if this timer is triggered in the final few minutes just in case.
- Is the area in which I am doing parallelization (at the individual image level) a good place to do it? Would it be better to parallelize things at the individual object level?
Multiband Histograms
As discussed, we want to see what our cutoffs might be across different bands. Thus, I have prepared the same scatter plots for every band. I attempted to fit 500 objects in all 7 images (G, R, I, Z, Y, U, U*) and have included the results. All the figures (including scatter plots) are included in the Dropbox under Figures/Multiband Testing if you would like to explore things further. To keep things simple, I have only posted the stacked magnitude and surface brightness histograms.
Surface Brightness Histograms







Magnitude Histograms







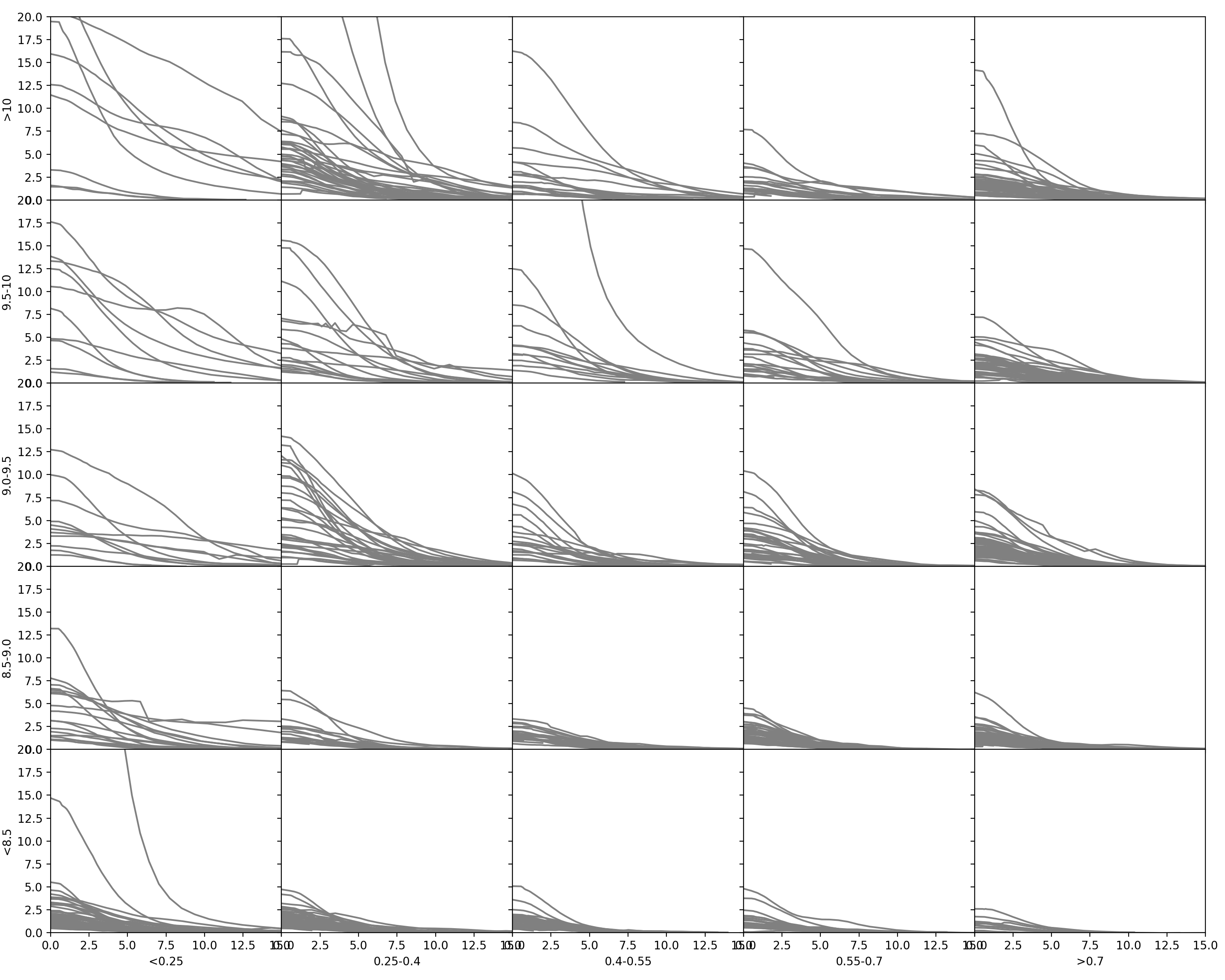
Matrix Plot Revamp
I realized early on that there is some motivation to rewrite the matrix plot code. The code, in similar fashion to the old pipeline, is very difficult to adjust or set up to work with the newly generated data.
I am currently rewriting the matrix plot code to better accommodate easier adjustments. It is now very easy to change the values for binning, or even the number of bins that exist. Below is the current iteration of the matrix plot, binned by mass on the Y-axis and Redshift on the X-axis. By tomorrow, there will be medians added to these plots.
Final Addendum
Moving forward, I have adjusted the catalogue to not have any cuts in either redshift or I-Band magnitude. These figures are not with this adjusted catalogue, but it shouldn’t make a hugely noticeable difference on what we see.




























